17跳表
大约 1 分钟
为什么Redis一定更要用跳表来实现有序集合?
跳表(Skip List)是一种给链表加索引的顺序表,支持类似“二分”查找算法
Redis中的有序集合就是用跳表来实现的。
对于单链表来说,即使链表是有序的,如果想要查找某个元素,只能遍历链。 这样查找效率很低,时间复杂度O(n)
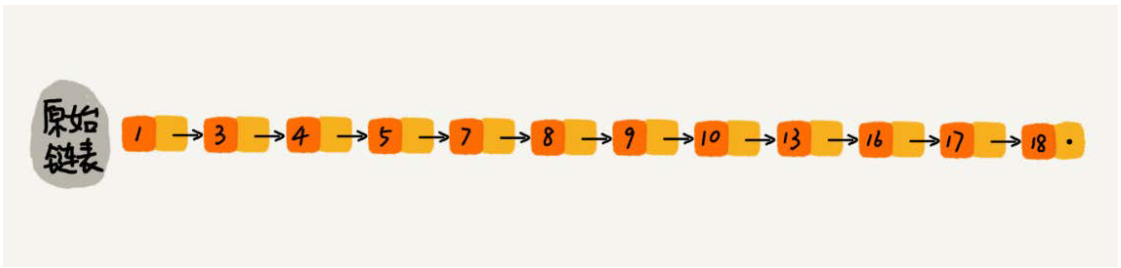
那么怎么提高效率呢?给链表建索引,两个结点提取一个结点到上一级,把抽出来的那一级叫作索引或索引层如下图
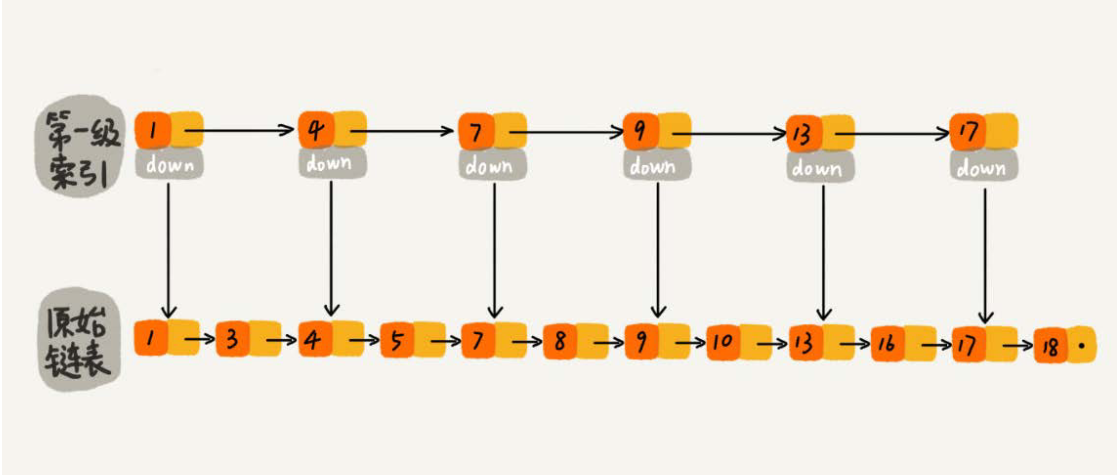
如果要找元素16,先从索引二分查找,小于17节点,取13节点,通过索引层结点的down指针,下降到原始链表这一层,继续遍历。只需要遍历2个节点,找到16。
数量不大建立索引提升效率不够明显,如果查找的链表数量很大,多级索引提高查找效率就很明显了。一个64节点的链表,按上面思路建立五级索引。
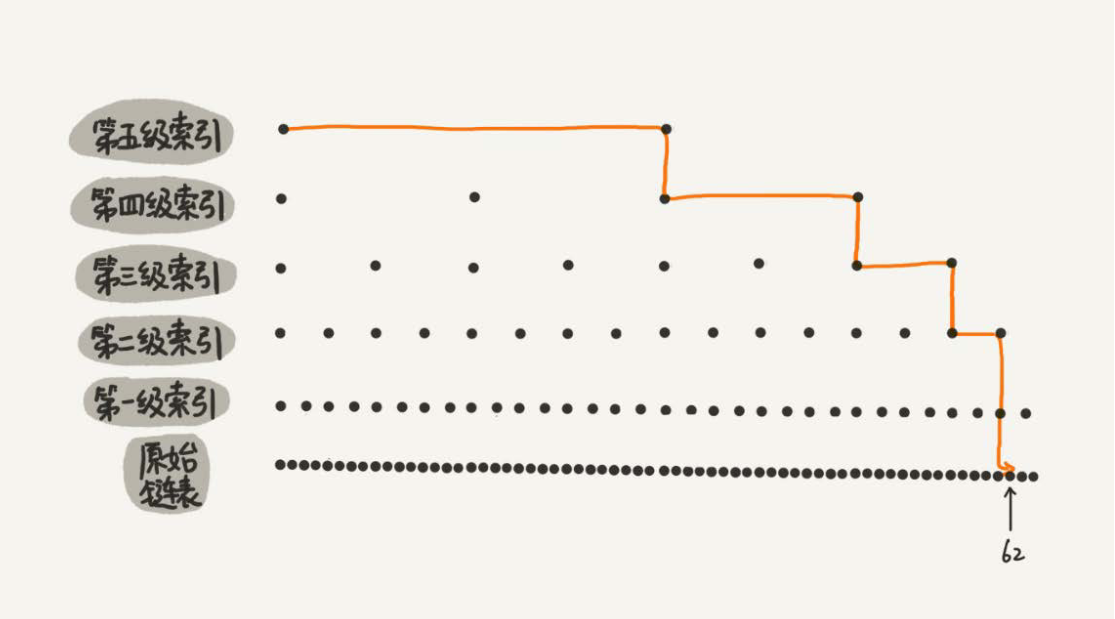
没有建索引时,查找62需要遍历62次,建立索引后,只需要遍历11次。链表长度n越大,查找效率提升越明显。
这里的算法思想是空间换时间。